




В DeepMind начали этот проект в 2014 году и с совершенно другой игры. Сначала они написали нейросеть для игры го. Alpha Go получила в своё распоряжение базу человеческих партий, с помощью которой обучалась игре, потом тренировалась против других программ, и в октябре 2015 года стала первой в истории компьютерной программой, которая нанесла поражение обладателю профессионального дана (чемпиону Европы Фан Хую) в серьёзной партии без форы.
В марте 2016 года состоялся матч Alpha Go против великого корейского игрока Ли Седоля, на тот момент занимавшего третью строчку в мировом рейтинге. Ли Седоль проиграл первые три партии, выиграл четвёртую, проиграл пятую и получил $150,000 за участие. Приз победителю матча $1,000,000 Google направил благотворительным организациям, в основном UNICEF.
В марте 2017-го Alpha Go сыграла матч из трёх партий с 20-летним китайским профессионалом Ке Цзе, сильнейшим игроком мира, c призами $1.5 млн и $300k. После матча (0-3) Ке Цзе сказал: «Человечество потратило тысячи лет, совершенствуя стратегию игры в го, но компьютер показал, что мы не смогли даже коснуться истины».
В октябре 2017-го DeepMind представили принципиально новую версию – Alpha Go Zero. Ноль в названии символизирует отказ от использования человеческих партий при обучении нейросети. Вместо этого в неё просто запрограммировали правила игры, после чего предоставили играть самой с собой.

Этого оказалось достаточно, чтобы через три дня обучения уничтожить первую версию Alpha Go со счётом 100-0, а через три недели с таким же счётом выиграть у версии, победившей Ке Цзе.
Подробный и довольно глубокий (сложный, как и сама тема!) рассказ о том, как работает алгоритм Alpha Go Zero, можно найти на Хабрахабре.
После матча Alpha Go с Ке Цзе команда DeepMind опубликовала 50 партий, сыгранных Alpha Go против Alpha Go. На этих партиях сейчас учится всё элитное го-сообщество. Ке Цзе после поражения радикально изменил свой стиль игры в дебюте (в частности, полностью отказался от ориентированных на влияние ходов в 4-4) и поставил личный рекорд, выиграв 22 партии подряд в профессиональных турнирах.
Программы семьи Alpha Go работают на тензорных процессорах (ноу-хау Google, оптимизированы для работы с нейросетями), а их код, разумеется, закрыт. Но направление работы уже указано, и по нему пошли многие другие. Сильные программы на базе нейросетей делают китайские и японские разработчики, тестируя их на игровых серверах против ведущих игроков и программ старого и нового поколения.

Существуют и бесплатные варианты. Создатель программы с открытым кодом – Leela, играющей в силу 9-го дана на сервере KGS, в октябре этого года выпустил версию Leela Zero, которая работает по принципу Alpha Zero. Учится она, правда, довольно медленно – бесплатному софту гугловские мощности не полагаются – и к старшей сестре за месяц с небольшим приближается медленно. Но неуклонно.
На этом закончим с го и перейдём к шахматам.
23 ноября 2017 года, интервью с Робертом Ударом, создателем топового шахматного движка Houdini:
Я с интересом следил за развитием истории с Alpha Go. Знаете ли, глава DeepMind Демис Хассабис – мастер по шахматам. Считалось, что го – более сложная игра, чем шахматы, но в шахматах подобную самообучающуюся программу создать не смогли. Успехи Alpha Go не имеют отношения к шахматам. Самообучающаяся программа, которая играет на равных с Houdini или Komodo – это выдумки. Может быть, Google попробует сделать нечто подобное? Кто знает.
Глава DeepMind в детстве был шахматистом и вроде бы даже неплохим – в Wikipedia пишут, что когда ему было 13 лет, по рейтингу в своём возрасте он уступал только Юдит Полгар. Весьма вероятно, что так оно и было – игрок с нынешним рейтингом (2249) давно не игравшего в турнирах Демиса Хассабиса (Великобритания) в чемпионате мира до 14 лет 2017 года был бы 9-м в стартовом списке. Как бы то ни было, следующим шагом Alpha Zero после го стали шахматы. (За компанию под раздачу попал также японский аналог шахмат – шоги, но их мы касаться не будем.)
Гром грянул 5 декабря, когда в интернете опубликовали статью Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm, подписанную коллективом сотрудников DeepMind. Они научили Alpha Zero правилам шахмат, после чего заставили нейросеть играть саму с собой девять часов. Сначала она делала случайные ходы, потом убирала из поиска неудачные и постепенно училась играть всё сильнее и сильнее. После окончания обучения она достигла сверхчеловеческого уровня игры. Доказательство – матч из 100 партий против одной из сильнейших программ «старого поколения», работающих по методу альфа-бета отсечения – Stockfish. Alpha Zero одержала 28 побед, 72 партии свела вничью и ни одной не проиграла. По ходу партий Stockfish оценивала 70 миллионов позиций в секунду, Alpha Zero – 80 тысяч: огромная разница, подчёркивающая мощь нейросети в умении отсекать ненужное.
Были также проведены тематические матчи в разных дебютах, по 100 партий на каждый. В них Stockfish удалось зацепить несколько побед, но перевес Alpha Zero всё равно впечатляет.
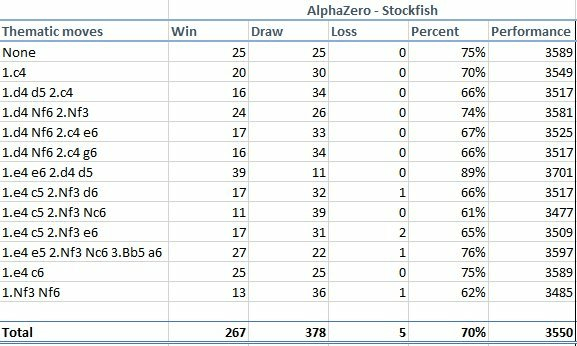
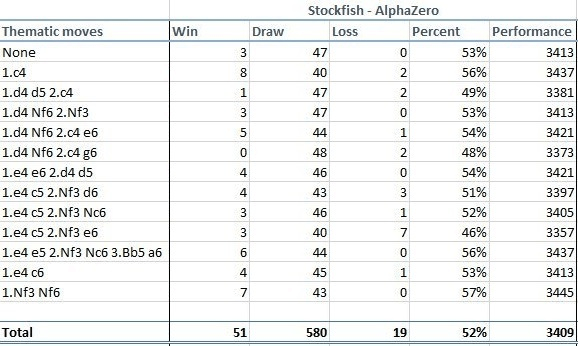
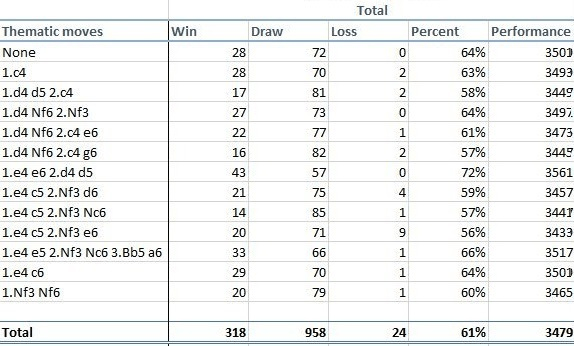
Уровня, равного Stockfish, Alpha Zero достигла уже после четырёх часов обучения, отсюда фигурирующая во многих источниках цифра. Но матчи, результаты которых были обнародованы, игрались с полностью обученной нейросетью.
В статье опубликовали десять избранных партий основного матча. Третий день ими восхищается весь шахматный мир. Это поистине космические партии, одну из которых мы покажем в конце статьи.

Гроссмейстеры уже научились жить в мире, в котором они проигрывают смартфону. Теперь они наблюдают за тем, как в одночасье на их месте оказались ведущие движки старого поколения, о которые вытирает ноги нейросеть, изначально созданная для другой игры.
Пара цитат из твиттера.
Йон Людвиг Хаммер, гроссмейстер (Норвегия):
AlphaZero с крупным счётом громит ранее непобедимую Stockfish. Играет в безумно атакующие шахматы на здоровой позиционной основе. По-моему, шахматы от этого стали ещё интереснее!
Евгений Перельштейн, гроссмейстер (США):
Хотите узнать, как Бог играет в шахматы? Посмотрите партии Alpha Zero, они дадут примерное представление.
Петер-Хайне Нильсен, гроссмейстер (Дания), тренер чемпиона мира Магнуса Карлсена:
Порой мне хотелось увидеть, как на Землю спускается превосходящая нас раса и показывает нам своё умение играть в шахматы. Именно это сейчас и произошло.
Критика
Шапочку из фольги в основном примеряют люди, занимающиеся шахматным программированием. Их эмоции можно понять – тысячи часов они корчевали пни и укладывали асфальт, в то время как под рукой лежал почти готовый телепорт, ведь нейросети – не какое-то сверхсекретное изобретение, а становящийся вполне стандартным метод решения ранее тупиковых проблем. Уже одно это заставляет меня с некоторым недоверием относиться к их претензиям к DeepMind. И всё же отчасти они, конечно, небеспочвенны.
Среди сомневающихся на удивление много опытных российских шахматистов. Их споры в фейсбуке читать порой смешно, порой страшно. Конечно, люди из очень закрытых профессиональных сообществ редко выглядывают за пределы этого кокона. Но не интересоваться происходящим в мире вокруг – это одно, а пылко отрицать то, чего не понимаешь – немного другое.
Есть среди недовольных чистотой эксперимента и люди, не имеющие отношения к шахматному программированию, но по каким-то причинам яростно болеющие за Терминатора Т-800 против Терминатора Т-1000. Может быть, они таким образом надеются отодвинуть Судный день?
Пройдёмся по главным тезисам.
Главная претензия к чистоте эксперимента – железо: AlphaGo играла на четырёх тензорных юнитах, а это безумная мощь, доминирующая Stockfish на 64 ядрах, которой, к тому же, дали всего 1 гигабайт хэша – мало! Разницу в быстродействии оценить чрезвычайно сложно из-за принципиального различия CPU и TPU, но обычно дают от 7 до 70 раз. Насколько существенно это влияет на силу игры – вопрос открытый, но как-то влияет точно.
Контроль времени, выбранный для матча – минута на ход, подходит нейросети и не подходит обычной программе, которая расходует время неравномерно – в начале больше, потом – меньше. А ошибки, сделанные в начальной стадии, исправить сложнее.

Версия Stockfish, использованная для матча, не была новейшей. Почему? Может быть (надеваем шапочку), программисты Google долго анализировали именно эту версию, чтобы «заточить» нейросеть Alpha Zero разорвать её в лоскуты? Добавлю, что разница в рейтинге между версиями составляет примерно 40 пунктов. Alpha Zero сильнее более старой версии Stockfish на 100 пунктов, то есть разница в матче с более новой версией была бы не столь впечатляющей.
Один из аргументов за использование старой версии Stockfish – именно она выиграла чемпионат мира среди компьютеров 2016 года. Да, слабее, зато чемпионка мира.
Stockfish якобы играла без дебютной библиотеки. Перечитал статью DeepMind, упоминаний об этом нет. Но, может быть, это подразумевается по умолчанию. Гроссмейстер Шипов утверждает, что её отсутствие видно из опубликованных партий. Alpha Zero тоже не пользовалась библиотекой, но её предшествующее самообучение можно расценивать как своего рода дебютную книгу. Некоторые опубликованные партии матча, в которых Alpha Zero шпарит по наиболее актуальным вариантам современных шахмат, подтверждают такое мнение. В тематических матчах по отдельным дебютам превосходство Alpha Zero упало со 100 пунктов до 77.
Где-то мелькали совсем уж конспирологические теории о том, что некий гроссмейстер-человек помогал Alpha Zero принимать стратегические решения. Обсуждать их всерьёз немного странно по нескольким очевидным причинам, но вообще было бы интересно протестировать в корректных условиях нечто подобное: усилит или ослабит компьютерную программу помощь человека по ходу партии...

Другим конспирологам, считавшим, что некоторые ответы Stockfish вообще чуть ли не подтасовали, ответил Александр Морозевич, проверивший ходы на своём компьютере и подтвердивший их совпадение (согласно сообщению Александра Динерштейна в сообществе «Игра го. Секреты мастерства»).
Основываясь на упомянутых выше вменяемых аргументах, скептики снижают силу Alpha Zero на 100-200 пунктов, а самые отъехавшие – и на все 500, приближая её по силе к Магнусу Карлсену (вот так унижение для компьютера!). В DeepMind редко снисходят до ответов на вопросы, но надо ли на такое отвечать вообще?
В оригинальной статье (вернее, конспекте – Хассабис обещает вскоре опубликовать и более полную версию) вкратце рассказывается, какие именно вводные получала нейросеть, в каком виде возвращала информацию разработчикам, прочие подробности. Выложили там и любопытнейшие графики изменения дебютных предпочтений программы по мере «взросления». Но на этом мы остановимся – все эти детали несложно найти на шахматных ресурсах, например, на chess24.

Выводы
Alpha Zero играла сама с собой всего девять часов, но это были часы на тех ещё стероидах – более 5,000 тензорных процессоров, разработанных Google специально для машинного обучения. За это время она сыграла 44 миллиона партий – в несколько раз больше, чем все шахматные профессионалы в истории человечества. Чтобы сыграть такое количество партий на обычном компьютере, понадобилось бы порядка 1,700 лет. Обучалась она на 64 тензорах второго поколения, примерная цена которых – десятки миллионов долларов. Повторить такое в домашних условиях смогут немногие, а Google вряд ли интересует ниша создателя сильнейшей в мире шахматной программы, чтобы портировать Alpha Zero на PC. Но дело не в этом. Результат эксперимента – доказательство того, что концепция является рабочей: нейросети могут эффективно работать в шахматах без дополнительной тонкой настройки (в DeepMind от неё отказались умышленно). На смену Stockfish и Komodo придут более сильные программы (может быть даже от тех же авторов), созданные по образу и подобию Alpha Zero, только, наверное, поначалу не такие космически могучие, как разработка DeepMind.
За комментариями мы обратились к одному из ведущих разработчиков проекта Isaac компании NVIDIA Виктору Маковийчуку.
В постановке экспериментов была PR-составляющая, конечно, как и во многих прошлых громких релизах DeepMind. Есть некоторые замечания по поводу использованного железа, например, что памяти на то количество ядер, на которых запускали Stockfish, должно быть больше, но в целом эксперимент выглядит вполне корректно поставленным. В чистых ФЛОПСах производительность железа, на котором запускалась Alpha Zero, выглядит гораздо больше, но стоит понимать, что это достаточно узкоспециализированное железо, и Stockfish на нём не запустишь.
Согласно оценке шахматистов уровня гроссмейстеров, Alpha Zero играла на качественно другом уровне, особенно доминируя в позициях с несимметричным материалом. С более мощным железом разрыв мог быть меньшим, но результат бы принципиально не изменился.
Многие сравнивают этот матч со Stockfish с матчем Alpha Go против чемпиона Европы Фан Хуя. К матчу были претензии и после него никто не верил, что Alpha Go сможет выиграть у Седоля. Но программа усилилась очень резко за прошедшее между этими матчами время.
Так и в случае со Stockfish, если вдруг решат организовать официальный матч против последней версии на более мощном железе, против него будет играть гораздо более сильная версия Alpha Zero, и результат будет столь же печальным для традиционных программ.
Ставить ли крест на шахматном программировании без нейросетей? Во многом это зависит от того, насколько идеи DeepMind могут быть хотя бы частично использованы в движках, разработчики которых не имеют ресурсов гугла для тренировки.
Да, главный эмоциональный аргумент в пользу мощи Alpha Zero – запредельные шахматы, продемонстрированные этой программой. Дайте Stockfish в сто раз больше времени на обдумывание, она всё равно не начнёт играть так. (Некоторые позиции из матча уже протестировали, и Stockfish не смогла найти выигрывающие ходы от Alpha Zero.) И я – любитель, кандидат в мастера, и гроссмейстеры, которых я опрашивал во время чемпионата России по шахматам в Петербурге, восприняли опубликованные партии примерно одинаково: игра огромной силы, бесспорно компьютерная по чистоте, но при этом на удивление «человеческая» по общей манере. Особенно впечатляют жертвы, выглядящие интуитивными – материал нередко отдаётся надолго и за довольно трудно формализуемые блага вроде пресловутой инициативы или позиционного зажима. Шокируют дебютные познания нейросети: она регулярно играет центральные варианты нынешней теории при отсутствии специально сконструированной дебютной библиотеки – дошла своим умом. Это можно понять в дебютах, в которых идёт прямая игра по центру, но как, чёрт возьми, оно придумало гамбитный вариант новоиндийской защиты?!
Будем надеяться, что, как и в случае с Alpha Go, DeepMind опубликует партии, в которых его движок играл сам с собой. Уверен, в них найдётся чему поучиться.
Alpha Zero – Stockfish
1. Nf3 Nf6 2. d4 e6 3. c4 b6 4. g3 Bb7 5. Bg2 Be7 6. 0-0 0-0 7. d5

7...exd5 8. Nh4
В этом ходе состоит суть гамбитного варианта новоиндийской защиты, который ещё называют вариантом Полугаевского. Белые отдают пешку, получая в качестве компенсации инициативу. Играя белыми, победы в этом варианте одерживали Полугаевский, Тимман, Каспаров, Мамедьяров... Современная элита вариант практически не играет.
8...c6 9. cxd5 Nxd5 10. Nf5 Nc7 11. e4 d5 12. exd5 Nxd5 13. Nc3 Nxc3

14. Qg4
Это пока не настоящая жертва фигуры, а временная – белые не взяли коня, но напали на мат в один ход. Конь не убежит.
14...g6 15.Nh6+ Kg7 16. bxc3 Bc8 17. Qf4 Qd6 18. Qa4 g5

19. Re1
А вот теперь всё по-настоящему! Stockfish на моём компьютере считает ход Alpha Zero проигрывающим, однозначно предпочитая ему сбежать конём на g4. Но чем дольше думает компьютер, тем сильнее корректируется оценка этого продолжения. На глубине 25 полуходов это уже не «зевок фигуры», а просто чуть худший ход, после которого чёрные впереди примерно на 0.7 пешки.
База анализов на сайте ChessBase показывает, что, во-первых, эту позицию смотрели и анализировали уже 843 раза, и Stockfish 8 на глубине 35 полуходов, хоть и продолжает предпочитать 19.Ng4, считает ход в партии ведущим к равной игре. Глубже вроде бы не заглядывали.
19...Kxh6 20. h4 f6 21. Be3 Bf5 22. Rad1 Qa3 23. Qc4 b5 24. hxg5+ fxg5

Следует оригинальный перевод ферзя на пассивную позицию в тыл – в стиле Тиграна Петросяна!
25. Qh4+ Kg6 26. Qh1 Kg7

27. Be4
Снова совсем не очевидный ход. Конечно, белые не берут ненужную пешку, ведь это избавит соперника от пассивного коня и соединит ладьи. Но – меняться? В позиции без фигуры?
27...Bg6 28.Bxg6 hxg6 29. Qh3
Белая пружина начинает медленно распрямляться. Чёрные ничего не могут этому противопоставить, разве что мстительно съесть ещё одну пешку.
29...Bf6 30. Kg2 Qxa2 31. Rh1 Qg8

32. c4
Stockfish на моём компьютере предлагает сделать активный ход 32.Rd6 с равенством. Ход Alpha Zero в его переборе третий. Судя по той же базе анализов, адская сила этого хода выявляется доступными нам программами на глубине под 40 полуходов. При более дальновидном расчёте разница в оценке очень велика – больше пешки!
32...Re8 33. Bd4
Alpha Zero cнова идёт на размен!
33...Bxd4 34. Rxd4 Rd8 35. Rxd8 Qxd8

У чёрных лишний конь и две пешки, но они гибнут после сурового тихого – без шаха или взятия – хода соперника.
36. Qe6
От угрозы шаха с е5 хорошей защиты нет. Stockfish не нашла ничего лучшего, чем откупиться материалом. Отдавать пришлось целую ладью, иначе на алтарь пошёл бы либо ферзь, либо король.
36...Nd7 37. Rd1 Nc5 38. Rxd8 Nxe6 39. Rxa8 Kf6 40. cxb5 cxb5 41. Kf3

Положение чёрных безнадёжно, через 15 ходов они сдались.






Огромное спасибо за настоящую журналистскую работу, Gipsyteam. Желаю, чтобы вы баловали читателей подобным гораздо чаще. Автору респект, жаль, что ты пожелал остаться неизвестным.
Судный день,приближается.
Ожидал увидеть матч в конце статьи в формате более удобном для просмотра.
Такой маленький, а уже скайнет
А почему не "судный,день,приближается"?
И ни одной шутки про Фан Хуя в комментах ((