
TL/DR
Учёные, которые ранее сделали Либратуса для NLHE HU, научили новую программу бить 6-макс. Плурибус учился покеру, восемь дней играя сам с собой на сервере c 64-ядерным процессором, после чего состоялся эксперимент. В ходе тестов Плурибус обыграл группу профессионалов, среди которых были Линус Лёлигер, Ник Петранджело, Даррен Элиас, Грег Мерсон и др. Программа работала не на суперкомпьютере, а на двух 14-ядерных процессорах и с памятью 128 Гб.
Победа над людьми в 6-макс NLHE – более впечатляющее достижение программирования, чем победы в Starcraft 2, Dota 2, го и шахматы.
Детали алгоритма публиковаться не будут, чтобы не навредить индустрии онлайн-покера. Авторы программы закончили эксперименты с покерным ИИ – для них эта игра пройдена.
Менее суток назад на сайте журнала Science и в блоге отдела искусственного интеллекта компании Facebook появились статьи Ноама Брауна и Туомаса Сандхольма, посвящённые завершению эксперимента по созданию программы, которая обыграет профессиональных игроков в безлимитный холдем за 6-макс-столом.
Эти фамилии нам хорошо знакомы – именно эти джентльмены работали над покерными проектами университета Карнеги – Меллона. Путь ИИ в покере начался с успехов в лимитном холдеме один на один – самой простой для машины игры ввиду отсутствия вариативности в ставках. Затем исследователи покорили сияющую вершину безлимитного холдема один на один. Хэдз-ап (если он без рейка) – игра с нулевой суммой, стратегическая задача была ясной, но бесконечное разнообразие сайзингов добавляло сложности. Тем не менее Либратус одолел группу ведущих профессионалов. Мы об этом тоже писали.
6-макс считался камнем преткновения – увеличение количества играющих за столом несоизмеримо усложняет вычисления традиционными методами. Кроме того, при выходе за пределы хэдз-апа возможны ситуации, при которых игра по равновесию Нэша может быть минусовой, что делает работу программистов ещё менее тривиальной. Поэтому победа новой программы Брауна-Сандхольма, которую назвали Плурибус, стала новым и, видимо, последним в покере рубежом. Впечатляет, что люди были обыграны с использованием куда меньших вычислительных ресурсов, чем в предыдущем проекте.
Работа над Плурибусом началась после того, как Ноам Браун получил работу в Facebook в подразделении по искусственному интеллекту. Туомас Сандхольм по-прежнему работает в университете Карнеги – Меллона, однако успел основать две компании по ИИ. Strategic Machine помогает усиливать ИИ в компьютерных играх и оптимизировать цены на товары на конкурентных рынках. Чем конкретно занимается другая компания, Strategic Robot, не раскрывается, но в прошлом году она заключила контракт с Пентагоном на $10 млн.
На стадии разработки активное участие принимал Даррен Элиас, звёздный МТТ-игрок и победитель четырёх турниров WPT, что является рекордом этой серии.

Сначала я играл против пяти ботов – каждый день, по много тысяч раздач на четырёх столах. Программа усиливалась очень быстро и буквально за несколько дней прошла путь от посредственности до игрока мирового класса. Прогресс был по-настоящему пугающим!
После этого авторы программы решили провести основной тест. Соревнования между Плурибусом и профессиональными игроками проходили в двух форматах. В одном из них пять Плурибусов играли против одного профессионального игрока. Таких экспериментов было три. В них приняли участие Даррен Элиас, бывший совладелец Full Tilt Poker, победитель главного турнира Мировой серии Крис Фергюсон, а также не имеющий достижений и титулов человек, имя которого при рассказе о событии редко упоминают непокерные СМИ – Линус Лёлигер. (Любителей тайн заинтересует тот факт, что об участии Линуса в этом формате говорится только в блоге на Facebook, но не в статье в Science.)

Второй формат – пять профессионалов играют за одним столом с одним Плурибусом. В этом эксперименте участвовали 13 человек: Линус Лёлигер, топовый МТТшник и инструктор Upswing Ник Петранджело, бывший мидстейкс-гриндер и чемпион главного турнира Мировой серии Грег Мерсон, а также достаточно известные (преимущественно турнирной игрой, но не только и не все) Сет Дэвис, Майкл Гальяно, Тони Грегг, Джейсон Лес, Донг Ким, Шон Руане, Тревор Сэведж, Джейкоб Тул, Даниэль МакОлэй и Джимми Чоу. Каждый игрок получал псевдоним, который просили скрывать от остальных участников эксперимента, компьютер играл под своим именем. Каждый день играли от трёх до восьми часов, в среднем часа четыре. Рассадка выбиралась в начале дня случайным образом, выбор соперников специально не рандомизировали, а руководствовались желанием и возможностями игроков.
Финансовая мотивация тоже присутствовала. Каждый игрок получал не меньше 40 центов за раздачу, но оплата росла в зависимости от результата (максимум – $1.6 за раздачу). В ходе обоих экспериментов было сыграно 10,000 раздач. Игра шла с блайндами 50/100 и стеком 10,000, одинаковым в каждой раздаче.
В первом эксперименте слабее других выступил Даррен Элиас, проигравший 4.02 бб/100 (стандартное отклонение 2.19 бб/100), Крис Фергюсон проиграл 2.52 бб/100 (стандартное отклонение 2.02). В статье в журнале Science эти результаты объединяют, что даёт Плурибусу винрейт 3.27 бб/100 со стандартным отклонением 1.49 бб/100 и обеспечивает общую победу с доверительным интервалом 95%.
В статье в блоге AI Facebook есть нюанс – третий участник эксперимента, LLinusLLove, показал винрейт -0.5 бб/100 со стандартным отклонением 1 бб/100. Возможно, объединение этого результата с двумя другими вело к какой-нибудь «статистической ничьей», так что в Science обошлись без Линуса. В любом случае, респект таким парням!

Во втором эксперименте Плурибус выиграл 4.77 бб/100 при стандартном отклонении 2.5 бб/100. Вероятность того, что он играет в плюс, превысила доверительный интервал 95%. Если бы игра шла на NL10k, Плурибус выигрывал бы около $1,000 в час.

")
В расчётах винрейтов использовался метод AIVAT , с помощью которого сглаживалось влияние везения при сдаче карт, что позволяло получать достоверные винрейты на дистанциях, в десять раз меньше привычных для покерных профессионалов.
Любители технических подробностей могут разобраться в тонкостях идей программистов самостоятельно (см. список источников в конце стати). Сообщается, что авторы использовали алгоритм минимизации потерь (Monte Carlo counterfactual regret minimization) и сократили глубину перебора – раздачи при анализе считались не до конца, а до некоего горизонта, чтобы снизить требовательность к вычислительной мощности. Благодаря этому обучение Плурибуса на одном из коммерческих облачных серверов обошлось бы всего в $150, а против людей он играл хоть и на очень мощном, но вполне обычном компьютере с двухъядерным процессором и 128 Гб памяти. Для сравнения, решение задач, которые ставились в предыдущих экспериментах команды, требовали вычислительной мощности стоимостью в несколько миллионов долларов.
Особо отмечается, что алгоритм не будет опубликован, чтобы не усложнять жизнь индустрии онлайн-покера.
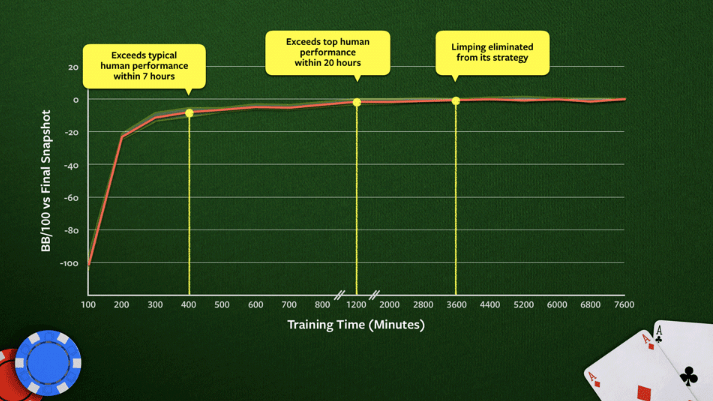
При обучении Плурибус превзошёл среднего игрока в покер за 7 часов, превзошёл элитный уровень через 20 часов и... окончательно отказался от лимпов со свободных позиций через 60 часов.
В статье в блоге AI Facebook приводится также четырёхминутное видео с некоторыми раздачами Плурибуса против пяти человек. Среди них – пуш 97 бб на флопе с мелким флеш-дро, после того, как соперник на первой позиции ставит контбет в трёх оппонентов; рэйз и 4-бет с As 7s с тремя улицами на постфлопе; три чека без позиции с топ-парой с третьим кикером – флоп чек-колл, тёрн чек-чек, ривер чек-рэйз на полстека. Все раздачи эксперимента можно найти по ссылкам в конце этой статьи.

Победа Плурибуса выделяется и на фоне других громких побед компьютера над человеком. Шахматы и го – игры с полной информацией для двух человек, прохождение которых упиралось только в глубину перебора и применение проходящих методов, когда достаточно глубокий перебор становился невозможным. В Starcraft 2 и Dota 2 специально разработанные программы не демонстрировали ничего особенного в стратегическом плане, но в боевых столкновениях управляли своими юнитами на сверхчеловеческом уровне, что гарантировало общую победу, если научиться исключать заведомо невыгодные стычки. Если бы в покерных олл-инах требовался микроконтроль, компьютер выигрывал бы у людей 100% выставлений Ax Kx в Qx Qx и выработать плюсовую стратегию стало бы совсем просто.
В целом ни для любителей, ни для профессионалов ничего особенного, наверное, не произошло. И до Плурибуса большинство играющих в покер остались бы в минусе против сильного бота. Теперь в зоне риска оказались и небожители самых высоких лимитов. Однако игра бота всё равно резко отличается от игры человека, и задача выявления искусственного интеллекта по базам раздач относительно тривиальна, нужны лишь желание рума и компетентная служба безопасности.
Цитаты
Даррен Элиас:
– Бот не просто обыграл группу средних профессионалов. Среди его соперников были некоторые из тех, кого считают лучшими в мире.
Сет Дэвис:
– Интереснее всего было бороться со смешанной стратегией на префлопе: в отличие от людей, Плурибус использовал разные сайзинги рэйза. Необходимость подстраиваться под нелинейные диапазоны опенрэйза делала эти матчи особенно интересными.
Тревор Сэведж:
– Игра с ботом стала для меня большим и очень полезным опытом. Бот играет в очень солидный покер на здоровой стратегической основе. Он часто заставлял меня принимать сложные решения, когда у меня была пограничная рука, и прекрасно добирал с лучшими руками. Я бы хотел поиграть с ним ещё раз!
Крис Фергюсон:
– Плурибус – очень трудный соперник. Ему почти невозможно положить руку. Он великолепно умеет тонко добирать на ривере.
Джейсон Лес:
– Плурибус невероятно хорошо блефует, намного эффективнее, чем любой человек. Именно поэтому с ним так тяжело. Ты регулярно оказываешься в ситуации, когда он делает большие ставки, и при этом знаешь, что он вполне может блефовать в любой момент.
Джимми Чоу:
– Когда я играю против бота, всегда стараюсь подсмотреть у него какие-то идеи. Люди склонны чрезмерно упрощать игру, ведь иначе выучить и успешно применять стратегию невозможно. Боту не нужно искать лёгких путей, и его варианты решения для каждой ситуации не только невероятно сбалансированные, но и исключительно сложные.
Шон Руане:
– В этой игре успех очень часто зависит от дисциплины мышления, концентрации, выносливости. Часами противостоять компьютеру, который не сталкивается с подобными проблемами в принципе – очень тяжелая задача. Технические находки и глубина игры бота, конечно, заслуживают похвал, но перед началом испытания сильнее всего я недооценивал именно его безупречную стабильность.
Майкл Гальяно:
– Плурибус применял некоторые приёмы, которые люди почти не используют, особенно касательно бетсайзинга. Стратегические приёмы от ИИ ускоряют эволюцию покера. Было приятно оказаться на переднем крае.
Дополнительные материалы
Популярная статья Ноама Брауна в блоге Facebook AI
Приложения к статье – постановка эксперимента и все раздачи с участием бота и его соперников