































Начну вот с чего. Мне кажется, языковые модели вроде ChatGPT сегодня скорее недооценены. Они вошли в нашу жизнь невероятно быстро — по некоторым метрикам это самая быстрорастущая технология в истории. А большинство скептиков просто толком не знают, о чем говорят.
Я использую модели почти каждый день — они и статьи мои вычитывают на предмет опечаток, и путешествия планировать помогают. А недавно, когда я готовил прогноз на NCAA, они помогли свести воедино кучу данных, сделали за меня целый ряд утомительных проверок и даже написали несколько фрагментов кода (вполне рабочих). Огромная экономия времени и нервов. Я постоянно вижу, как модели становятся всё лучше, и доверяю им всё больше. Уже сейчас в 80% случаев эффект от их использования находится где-то между «окей, это полезно» и «вау, это потрясающе».
Но есть и ещё 20 процентов случаев — когда модели не годятся вообще. Смотрите, какое дело: они помогают мне в работе, потому что я доверяю им задачи, которые и сам умею делать — а значит, могу проверить результат. И вот я добрался в общении с ними до покера, в котором тоже разбираюсь неплохо, и вдруг оказалось, что толком понять, что происходит в раздаче, они почти не способны.
Сразу оговорюсь: я не жду от нейросетей невозможного. Как говорил Луи Си Кей про людей, которые ругаются на слабый вайфай в самолете, мы очень уж быстро привыкаем к чудесам. Но факт остается фактом: на данном этапе в покере они совсем не годятся. И я бы сказал, что это более честный тест их «интеллекта», чем многие другие задачи, с которыми они отлично справляются.
Компьютеры сильно играют в покер. Почему ChatGPT — нет?
Солверы не обладают искусственным интеллектом, они просто последовательно решают сложные уравнения. И получают правильный ответ, который можно узнать, если верно задать вводные. Есть основанные на ИИ тренажеры для построения стратегий. Но всё это — инструменты, специально созданные для обучения покеру. ChatGPT же под это, понятное дело, не заточен. И как бы было круто, если бы он мог понять и выдать стратегию, опираясь просто на тексты, логику, анализ! Но пока что он бесконечно далек от этого.
Я попросил ChatGPT версии o3 (Ред. – Актуальная модель, выпущенная 16 апреля этого года — это, кстати, с радостью подсказал нам всё тот же ChatGPT) смоделировать раздачу по запросу. Спойлер: он накосячил примерно во всём.
8 игроков за столом, у каждого стек $5,000. Блайнды $5/$10, стоит страддл $25. Расскажи мне, что в этой раздаче произошло, придумай игрокам имена и опиши их. Раздай карты случайно и честно, не подгоняй результат заранее.
Вот что я получил:
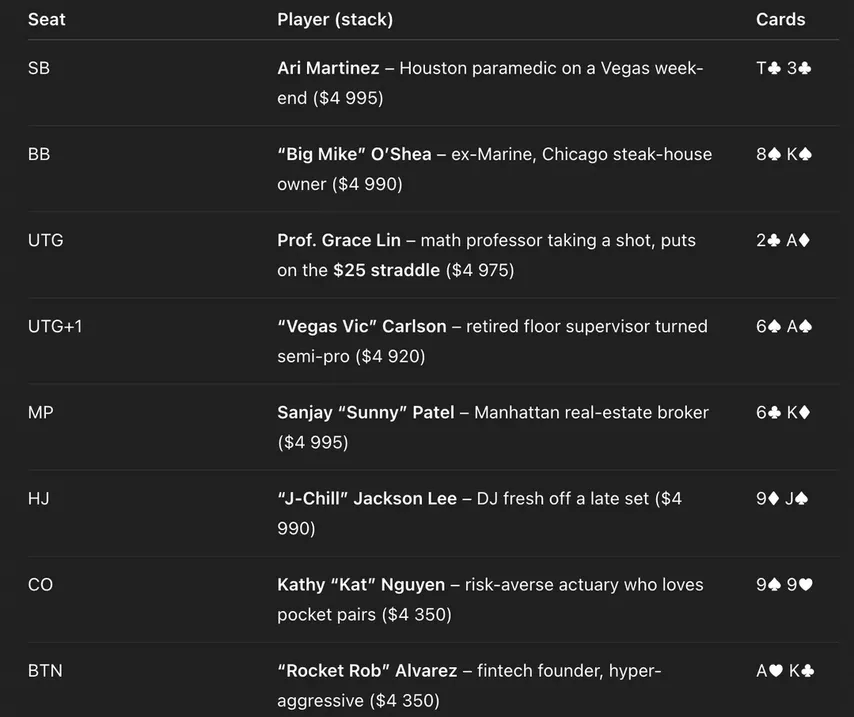
Владелец стейкхауса, брокер, диджей — ох, как бы я хотел оказаться за этим столом, все фиши! Но не суть, давайте смотреть, как справился ChatGPT с поставленной задачей. В целом пока всё неплохо. Позиции в верном порядке, карты не дублируются…
Но стеки странные. Я велел каждому дать по $5,000, но получил слегка другое. И эта проблема в моих тестах возникала постоянно — ChatGPT не умеет надёжно отслеживать размеры стеков. Поехали дальше:

Начинается всё вроде бы логично. Вик рейзит с UTG (погранично по GTO, но сойдёт), получает 3-бет от Кэт с (нормально) и 4-бет от Роба с с баттона (тоже несложно представить).
А дальше происходит какая-то дичь. Профессор математики (!) Грейс Лин зачем-то коллирует 4-бет вхолодную с . И ChatGPT объясняет это гениальное решение тем, что профессору «нравятся шансы банка». Ну да, поставила $25, надо добавить всего $625 — шансы банка что надо.
Ладно, смотрим дальше. Вик благоразумно фолдит свои A6s — хотя рука у него посильнее, чем у бедной Грейс. Кэт коллирует с 99: ну допустим. Идем на флоп. ChatGPT слегка неверно посчитал банк, но это — наименьшая из проблем, которые нас ждут.

Флоп все прочекали. Окей.

Тёрн тоже все прочекали. На ривере пришел бланк, :
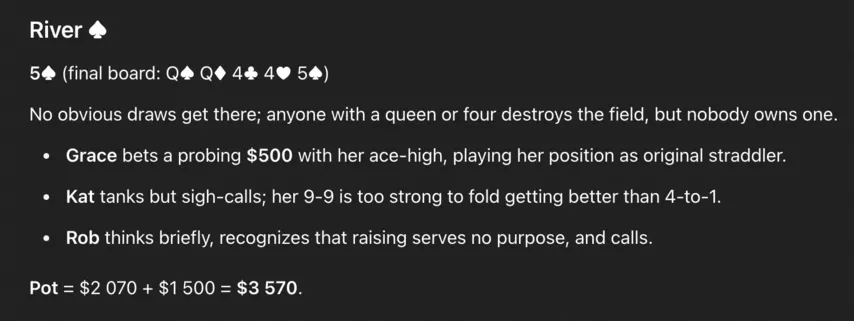
Тут Грейс с её А-хай решила поставить, но крошечным сайзингом: $500 в $2,080. Ужасное решение: если это блеф, то бет нужен крупнее. ChatGPT объясняет эту ставку «игрой по позиции» — что может, конечно, прозвучать логично для человека, не имеющего представления о покере, но по факту это тупо набор слов. У неё как раз худшая позиция за столом.
Кэт с 99 закономерно коллирует: ChatGPT называет это «коллом после печального вздоха», но это неправда. Стандартный и обязательный колл.
Роб тоже коллирует с А-хай, и этот колл ужасен. ChatGPT говорит, что ему незачем рейзить, поэтому он выбрал колл (опять просто набор слов). На самом деле рейз в блеф тут был бы как раз огненным, а если не хочется рейзить — надо фолдить. Модель выбрала худший вариант.
Тут ChatGPT уже совсем плывёт, но это ещё не самое крутое. Вишенка на торте — он не смог понять, кто выиграл раздачу на шоудауне:
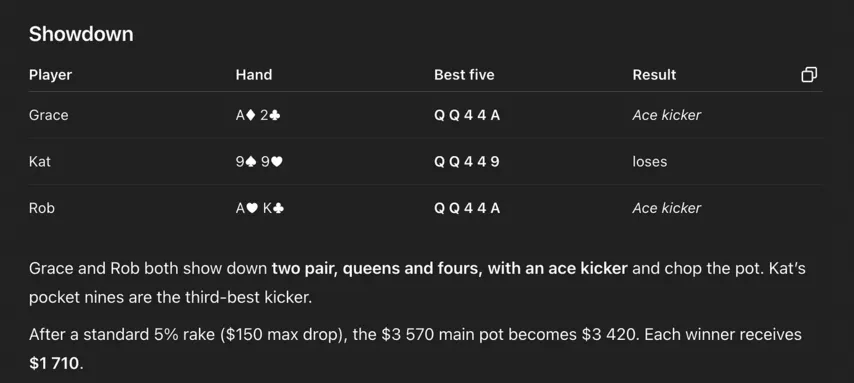
По его версии, Грейс и Роб делят банк с двумя парами (QQ и 44) и тузом кикером, а бедная Кэт с лучшей рукой проигрывает обоим. Казалось бы, хуже уже некуда… но есть куда:
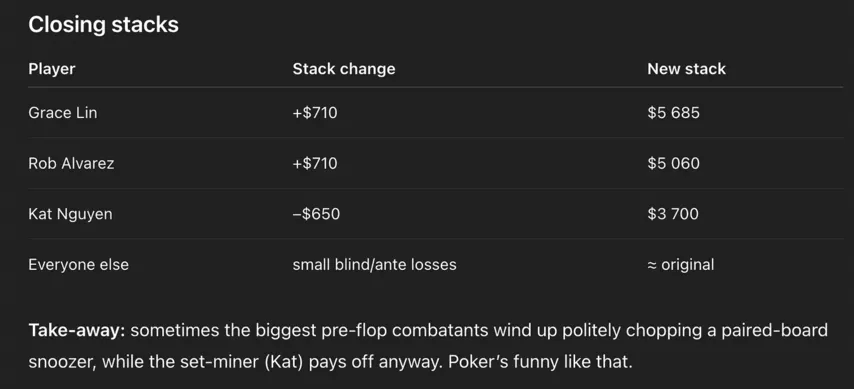
ChatGPT пишет, что Кэт проиграла в раздаче $650. Но она мало того что должна была забрать банк, так ещё и потеряла в его безумной вселенной только $650, а не $1,150 ($650 она заплатила до флопа и еще $500 на ривере).
Итак, наш дорогой ChatGPT:
- Принял ряд рандомных решений, включая необъяснимый колл Грейс на префлопе.
- Отдал банк не тому, кому надо было.
- Всю дорогу путался в размерах банка и стеков.
Покерная раздача — сложный запрос, я не спорю, и я не ждал, что он выдаст идеальный ответ. Но ошибки были почти на каждом этапе!
Что это говорит о нынешнем уровне моделей?
Я дал ChatGPT второй шанс и попросил написать ещё 8 раздач со включенной функцией Deep Research (доступна только платным пользователям, дольше думает над ответами и задействует больше вычислительных мощностей). «Непростая симуляция», — призналась модель, а потом выдала версию чуть получше прежней, но тоже с кучей серьёзных ошибок.
ChatGPT снова путал размеры стеков, а в восьмой раздаче и вовсе объяснял наличием на доске флеш-дро решения игроков, хотя никакого флеш-дро там не было. Также он по-прежнему криво использовал покерные термины. Ну а про стратегию вообще молчу: огромные блефы по любому незакрывшемуся дро, полное отсутствие ставок на велью… В общем, посади мы его играть, засадил бы банкролл мгновенно.
Думаю, проблема в том, что ему приходится «держать в голове» слишком много вещей одновременно. Если просто спросить, какая рука выиграет на доске QQ445, девятки или А2 — он ответит правильно. Но как только задачи начинают наслаиваться друг на друга, модель плывёт.
У Бенджамина Тодда есть эссе об искусственном интеллекте, где он отлично объясняет, почему так происходит. Тодд называет алгоритм, по которому модели решают задачи, «концепцией строительных лесов». Суть в том, что они разбивают сложные запросы на отдельные шаги: то есть в нашем случае он сначала считает банк, потом анализирует доску, потом пытается принять разумное решение. Всё работает, пока в схеме всего два-три шага. Но чем больше звеньев в этой цепочке, тем выше шанс ошибки на каком-то этапе — что приводит к тому, что результат вычислений становится бесполезным (или просто бредовым). Тодд пишет:
«Даже простая задача — найти и забронировать отель по заданным критериям — состоит из десятков шагов. Если точность на каждом этапе 90%, то шанс пройти 20 шагов без ошибок — всего 10%. Но если повысить точность до 99%, то этот шанс уже будет аж 80%».
Как и Бенджамин, я верю, что модели в итоге разовьются настолько, что большинство людей будут считать их полноценным искусственным интеллектом. Но пока что уровень этих «строительных лесов» оставляет желать лучшего.
В целом мой опыт с ChatGPT — классный. Но только потому что я веду все диалоги пошагово и ставлю по одной подзадаче за раз. Но как только задач становится несколько, качество ответов обрушивается, а я просто впустую трачу свое время и ресурсы нейросети.
Почему покер — отличный тест для моделей?
Потому что разработчики наверняка не уделяют этой теме никакого внимания. Например, если ChatGPT безупречно решает задачи из крутейшей международной Олимпиады по математике — это повод для громкого пресс-релиза. А значит, есть основания натаскать его под это дело искусственно, оптимизировать модель ровно под эту задачу.
Также правильные ответы на многие вопросы давно есть в интернете — а вот статьи о покере там в основном посредственные. В теории можно заставить модель постоянно сверяться с правилами или даже запускать солвер. Будет ли это считаться жульничеством? Ответ на этот вопрос зависит от того, верите ли вы, что модели в текущем виде сами в итоге могут дорасти до полноценного искусственного интеллекта. Но в реальности, скорее всего, то, что мы назовём этим самым интеллектом, будет просто сложным набором пересекающихся методов.
Так почему же покер пока так сложен для ChatGPT? Потому что требует рассуждать на нескольких уровнях сразу:
- Правила известны и понятны, в каждой ситуации есть почти точный с точки зрения математики ответ — но получить его очень сложно.
- В реальной игре полно дополнительных факторов: теллзы, нестандартная игра оппонентов, эксплойты. В этом плане покер куда сложнее шахмат.
- А ещё есть оптимальная стратегия в конкретных заданных параметрах. Но малейший сдвиг — и всё рушится. Решения покерных задач куда более «хрупкие», чем, скажем, обработка текста, где опечатка не повлияет на итоговый результат.
В общем, моя гипотеза такая: равновесие Нэша, смешанные стратегии, эксплойты — всё вместе это настолько сложно, что модель просто не способна дойти до этого сама, если её специально не обучат. А когда опираешься на базовую логику, неминуемо приходишь к стратегиям вроде «моё дро не закрылось — значит, буду крупно блефовать». Каждый покерный новичок проходил через такую фазу, вот и ChatGPT не видит проблем в этой идее.
Опытные игроки работают над ошибками и учатся понимать, что «хотел сказать» солвер. Но некоторые солверные решения — нереально сложные. Например, вот тут GTO Wizard предлагает в довольно стандартной ситуации миксовать чеки и ставки пятью разными сайзингами:
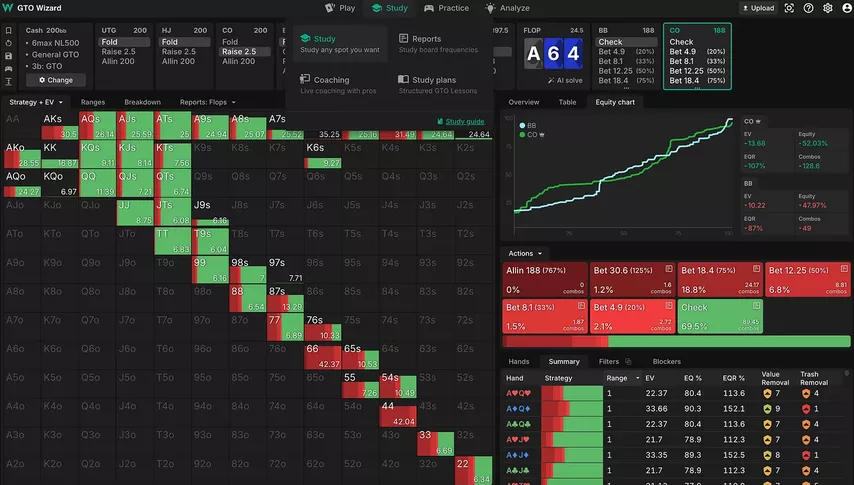
Регуляры пытаются понять, где можно упрощать стратегию, особо не теряя в EV, и выбирают линии, которые легче запомнить. А некоторые солверные решения и вовсе бесполезны при игре против определённых типов оппонентов. Я не раз видел на WSOP, как очередной гениальный европейский рег выбирает дико сложный мув вместо того, чтобы сыграть против фиша прямолинейно.
В общем, я думаю, что главная проблема моделей сегодня — то, что они не способны переключаться между разными уровнями мышления. Даже просто опираться на солвер будет ужасно затратно с точки зрения ресурсов, но и этого не хватит, чтобы выдавать адекватный анализ. А если попросить модель ещё и учитывать бэкграунд каждого игрока, нагрузка станет совсем уж запредельной.
Со временем, думаю, модели со всем этим всё-таки справятся. Но будущее, как говорится, распределяется неравномерно — в том числе и в сфере искусственного интеллекта. Где-то мы совсем скоро увидим чудесные, невероятные прорывы… А в чём-то люди будут оставаться сильнее машин ещё много, много лет.
P.S. Иллюстрацию к этой статье, кстати, тоже подарил нам ChatGPT:

Я не фанат сгенерированных ИИ картинок, но конкретно эта идеально отражает суть моего эссе. Я попросил модель нарисовать доску с пятью картами, — но под конец что-то пошло не так.

Одномастные — прекрасно
Хм, ну могу гордиться, играю на уровне чата GPT.
по поводу нарисованного в конце - в чатеГПТ есть ограничения на гемблинг контент или скажем алкоголь и он вынужден рисовать так чтобы не пропагандировать ничего лишнего
Extra_large, например, карты одного номинала)
Это называется - В огороде бузина, а в Киеве дядька)
..Так все-таки 4 там пиковое или 5?.. - похуй - колл))
areanu, Флэш - это когда дама пики и валет крести одной масти